 |
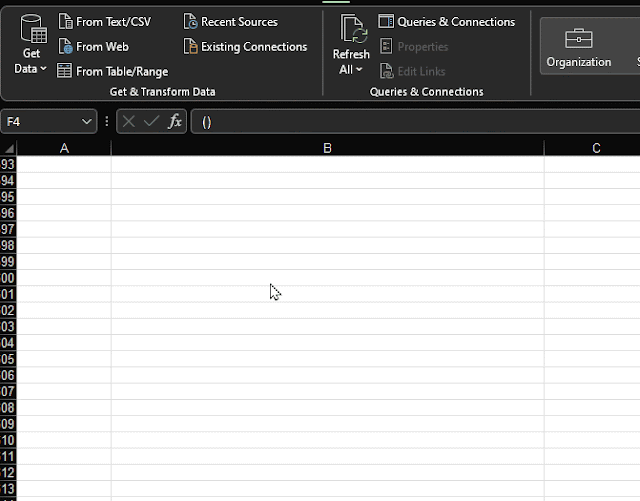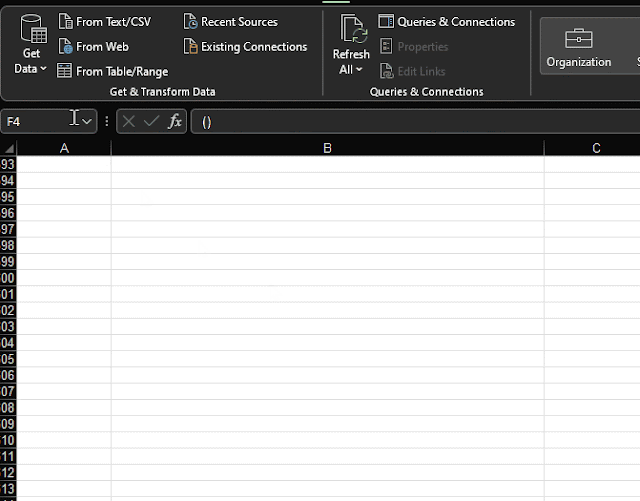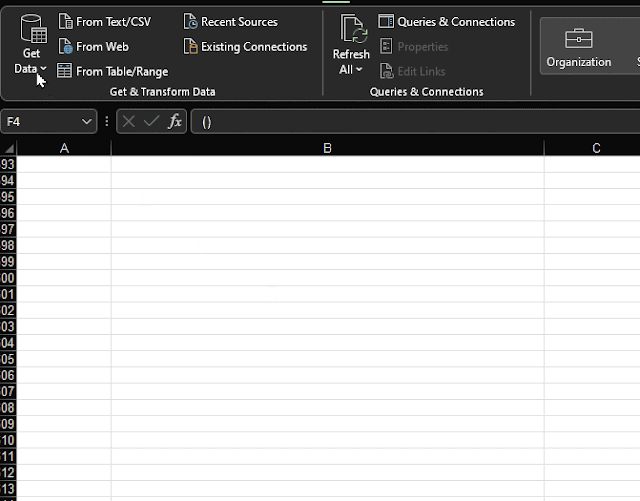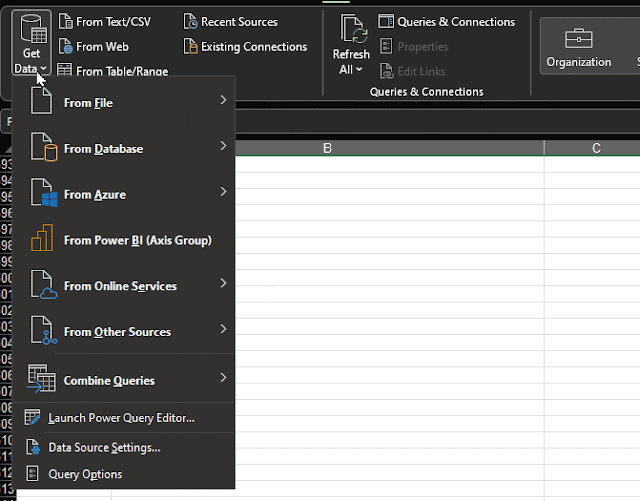
| Get Data. |
Disclaimer: This post will not substitute for basic training on how to use Power Query!
I was recently on a project involving disparate, unexplored data, a BI platform without ETL capabilities, and a locked down machine/environment where I was not allowed to install anything. This made understanding the data and testing assumptions and business rules to help the ETL team difficult.
Fortunately, there was a hidden solution on my machine that is likely on yours, too: Power Query. It's an application hiding in Excel (Data tab -> Get Data) that can connect to a variety of data sources and supports a plethora of code-free data wrangling. You can use it as a pseudo-SQL client to run one-off queries or generate datasets for Pivot Tables or BI prototyping. And if you're only browsing and exploring data, especially from several sources, it seems preferable to a SQL client like SQL Server Management Studio.
I learned to use Power Query in the context of Power BI, but this project was my first attempt to use it as part of Excel. Based on this experience, I can see a lot of use for it in common scenarios …including replacing and automating common "Excel hell" situations.
Problems Power Query solves
Almost codeless data discovery: browsing, filtering, viewing distinct values, profiling, etc., with live data
- How many times have you selected top n from the same table to browse representative data? In Power Query, add a query for each table you might use, and you can always click back to those queries to browse the previews. Queries for a single project are easy to save, organize, recall, and refresh.
- What's the next question after you select top n? The Power Query interface enables you to filter, sort, and view distinct values, with an interface identical to Excel, without writing SQL. SQL clients don't do that. They look the same as they have for 20 years, and they only work for databases.
Transformations can usually be done without writing code. It's a great interface for rapid prototyping with business users looking over your shoulder.A familiar interface - Previews of query results are updated immediately when you do transformations. Even though only the first 1000 rows show in the preview, you can use the entire result set as the source for other queries. This works well for QA and profiling queries that are easy to rerun as you iterate and see what changed, as described in this post.
- Power Query pushes work upstream and leaves data where it is
(until you do something that requires moving it to your machine). Most
common transformations, like filtering, aggregation, and joins are
automatically translated to SQL and run directly in the source system,
returning only the results. There are limitations to this, discussed
below.

Treats all source data formats equally, from the same interface
- Power Query wizards don't always generate the most efficient code, but the experience is the same, whether you're loading from a relational database or delimited files. There's no need to learn minor variations of SQL, depending on the source platform. It can even join datasets that are not the same format, like a database table to a spreadsheet.
- Maintenance is minimized because the language it generates (M) is the same, regardless of the data source. So, if you get a real database to replace a CSV data dump, you can switch to the new source and execute the same queries without any rewrite.
- It's generally the best option for prototyping with files, because there is no SQL client to explore, profile, and transform files.
Generate sample dataset for BI development while ETL developers are at work
- The cost to iterate is much lower in Power Query compared to having to rebuild database tables with every tweak. This is where to test business rules before implementing them in data layers.
- For the project I mentioned at the start of the post, I generated a sample schema using Power Query, outputting each "table" to its own sheet in the spreadsheet. This gave the BI developers something to work with for their UI while we waited for the data layers to be built by the ETL team.
…Pretty much any error-prone thing people do in Excel with crazy functions
- No more VLOOKUPs or other brittle code, where humans may not copy their formulas as thoroughly as intended. Power Query treats a spreadsheet data source more like a database table than an array of individual cells. It won't accidentally miss a row.
- If you know somebody who gets a file each week and manually adds the same few formulas and derived columns, Power Query can automate that to a one-click update. The trick is to separate the source data file and the Excel file with the Power Query logic. The Excel file with Power Query can read the other spreadsheet as a data source, apply business rules, and output the result to a sheet in itself. This enables the source file to be updated independently, then just click refresh in the file with Power Query to update the results.
Things to remember
- There isn't always a wizard or shortcut to do what you're looking for. When you must write your own code, M is not user-friendly or SQL-like (but that's for another post). If you have learned Power Query because you have learned Power BI, you will have a leg up here: optimizing or reducing the number of steps is certainly easier if you already have familiarity.
By default, Power Query loads every query's result into the sheets of the spreadsheet. If a query is just for exploration or an intermediate step, you must change it to "Load To" Only Create Connection. (If you are used to Power Query in Power BI, this is kind of like disabling the query load.)Load To -> Only Create Connection - For file-based source data, keep the files local, if possible. Otherwise, you will essentially be downloading the files every time you run a query.
- Query folding, i.e., M code automatically translating to SQL and running natively in the source, matters a lot for performance. As soon as a query reaches a step that can't fold, all data must be transferred to your machine to do the work there. Basic transformations can break folding, like changing data types or adding a hard-coded value. It can't always be avoided, ex., joining data from different sources, but the effects should be minimized. For large datasets, this can be significant or be beyond the limits of what your machine running Excel can do, hence the next bullet.
Query folding adage: "If the text is black, the query folds for Jack. If the text is gray, it might run all day." - Filter out or aggregate data early in the steps of your transformations. These steps are virtually always foldable and avoid sending large amounts of data to your machine and into memory. Query folding only applies to SQL data sources but filtering early helps with any data source to reduce resource needs on your machine.


I didn't have familiarity with Power Query outside of Power BI until recently, but now I sincerely believe it could help a lot of everyday spreadsheet jockeys who don't know what's hiding in Excel right now. I may never write a VLOOKUP again.