 |
| Click for larger image |
I just published another post on Data on the Rocks, a superblog with writers from around the world sharing their knowledge about the Qlik ecosystem.
Recipe for simple driver analysis (Data on the Rocks)
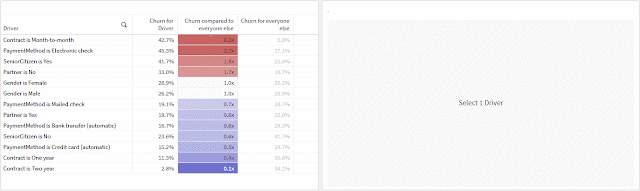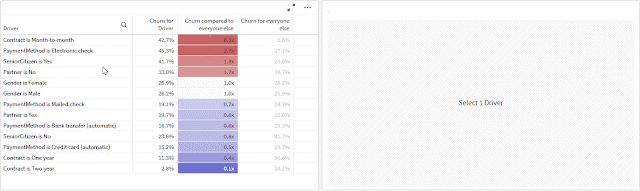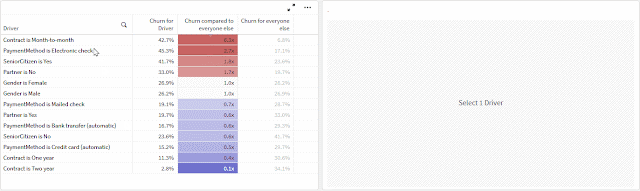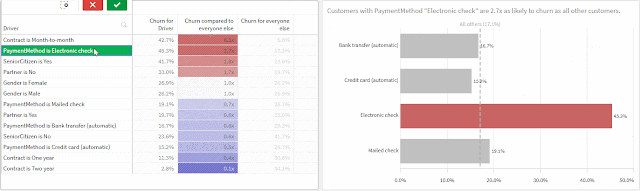
This post outlines how to build output that goes beyond the typical aggregate analysis in finding potential influences for minimizing or maximizing a metric -- churn, in this example.
The solution requires overcoming two technical hurdles:
- Comparing many fields at the same time without having to cycle through them — accomplished through the data model
- Comparing a population’s churn to the churn for the population excluding itself, not just the overall average — accomplished through an expression
The second point is more interesting than it sounds. I think people often compare data points to the entire population that contains them to look for outliers, but you're more likely to find insights by removing the data point you're studying from the population to isolate its influence. If one slice of data makes up the majority of a category — ex., if nearly all customers have just one line — comparing the churn for customers with one line to the overall average churn is unlikely to reveal anything because they’ll be so similar. But by comparing to the population excluding customers with one line, we are more effectively isolating the variable or driver.
Churn is one example, but the recipe is easy enough to follow to apply to your own applications. It requires adding just one key field and a small associated table that can live comfortably alongside your existing guided analytic solution.
Details can be found in the linked post.